Речь пойдёт про сеть, про людей и капельку про сервера.
Про то, как из состояния «полная жопа» в инфраструктуре прийти к более-менее нормальному.
Читать далее Про успешное преодоление длиной в два годаРечь пойдёт про сеть, про людей и капельку про сервера.
Про то, как из состояния «полная жопа» в инфраструктуре прийти к более-менее нормальному.
Читать далее Про успешное преодоление длиной в два годаЕсть SL — то, на сколько процентов звонков успели ответить в течение первых N секунд звонка. Целевой показатель 80% за 20 секунд.
Запрос от колл центра: «нам нужно что-то такое, что покажет, насколько всё плохо с временем ответа». Мы побеседовали и уточнили запрос до следующей формулировки: «если просрали SL и он упал меньше 80, то понять как сильно нам нужно исправиться, чтоб вписаться в SL 80% за 20 секунд».
Сегодня я предложила несколько вариантов. Насколько я поняла, цель не сократить среднее время ответа, а вписаться в SL 80/20. Поэтому наиболее, на мой взгляд, подходящий показатель, это 80й перцентиль по времени ответа по всем звонкам. Это такое число секунд Х, которое покажет, что 80% звонков было отвечено за время меньше Х, а 20% за время больше Х.
При SL ровно 80, 80й перцентиль будет ровно 20 (при одинаковой базе, например, везде отбрасываем звонки менее трех секунд). Соответственно, когда SL уходит менее 80%, 80й перцентиль будет более 20 секунд. И теперь, посмотрев на SL и на перцентиль, можно понять, как сильно надо исправиться, чтоб догнать SL до 80. Например, SL 74, а 80й перцентиль 22 секунды. Мы понимаем, что 6% звонков, которых нам не хватает до целевых показателей, были отвечены за время 20-22 секунды, с ними и надо работать, чтоб догнать SL. (Ща, менеджмент, выдохните, дальше будут ещё предложения). Или второй пример, SL 75, 80й перцентиль 40 секунд. То есть 5%, которые просрали нам показатели, были отвечены в период 20-40 секунд. Ситуация выглядит хуже, хотя SL лучше.
Но на самом деле, не факт, что работать нужно именно с теми звонками, которые слегка не дотянули до показателей. Может наоборот, надо работать с самыми длинными ожиданиями или с теми, кто чаще встречается или ещё что. Так что предложены альтернативы:
Мой телеграм канал, где я пишу про работу системным администратором:
Общий пост про DHCP-failover тут
Было время, лет 7-8 назад, у нас начал помирать сервак с dhcp. Был он физический в те времена, не виртуальный, и помирал внезапно и всегда не вовремя. На винде DHCP был, потому что там приятненький интерфейс, так исторически сложилось, а также потому что, так или иначе, в dhcp лазили четыре человека, а в роли линух-админа наблюдалась только я (не то чтобы я считала себя гуру, но на фоне остальных вполне прокатывала за линуксоида). Я тогда полезла изучать вопрос, а может придумали нормальное резервирование без бубнов, да на винде — и таки да, с Windows Server 2012 завезли failover. Не нужно пилить диапазоны или извращаться, настрой и пользуйся.
Божечки, какой же это кайф! Отказоустойчивость в случе, собственно, отказа занимает только половину профита. Представьте, что у вас человек (ваш сервис dhcp) стоит на двух кубиках (серверах) двумя разными ногами, а рядом есть ещё кубики. Он может поднять одну ногу с кубика и переступить на соседний, не потеряв равновесия. Или постоять на одной ноге, пока вы поменяете кубик. То есть, надо винду на серверах проапгрейдить? Разрушаете failover, обновляете на одном сервере, восстанавливаете faillover, потом то же самое, но со стороны обновленного сервера. Перевезти сервера в новую сеть? Разрушил failover, создал отношения с сервером в новой сети, разрушил с нового сервера, создал со вторым сервером в новой сети. Только relay не забывай прописывать на сетевом оборудовании. Всё, 8 кликов, бесшовно, без потери текущих лизов. Огонь же, до сих пор кайфую, когда надо перевезти dhcp и это не требует усилий, работы ночами и вообще не напрягает.
Речь про обычные офисные сети с пользаками/телефонами где из выебонов максимум пару не включенных в стандартную поставку опций, типа 150 и 252, вкачены. Да, ок, если есть нестандартные опции, добавляется ещё пару кликов — создать их на новом сервере. Всё равно охуенно удобно.
Мой канал в тежке про всякое админское:
Failover — ближе всего термин «отказоустойчивость», был придуман для обеспечения высокой доступности каких-либо сервисов. Вы дублируете какую-то часть системы или даже систему целиком для того, чтобы при отказе ваши пользователи не остались ни с чем. Круто, когда для пользователя отказ пройдет незаметно. Неплохо, когда отказ повлечет небольшое снижение качества услуги. Плохо, когда пользователя пошлют далеко и надолго просто потому, что всё сломалось. Это было так, лирическое отступление.
Теперь что касается DHCP. Задача сервера тут состоит из двух частей: выдавать адреса (каждый раз добавляйте мысленно «и сопутствующие настройки») новым пользователям и продлять аренду адресов для уже существующих клиентов.
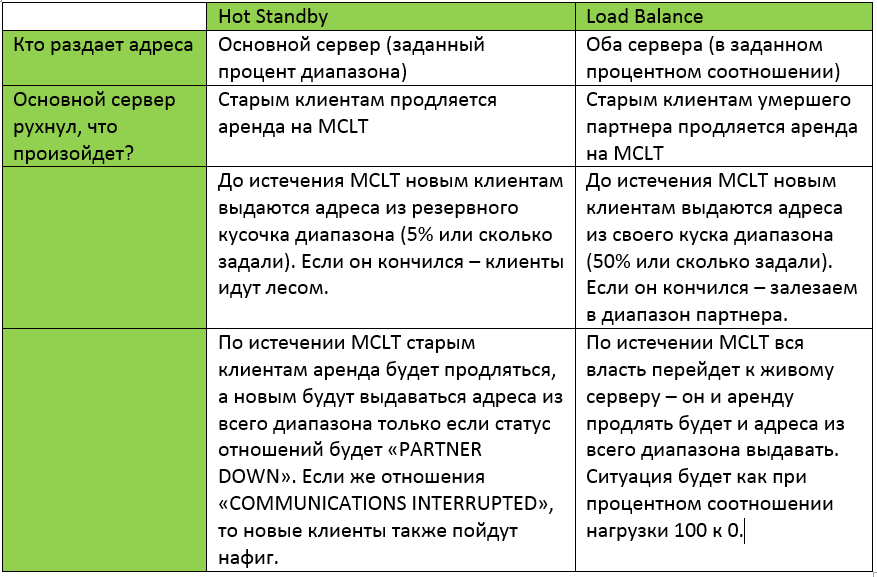
Классические принципы построение отказоустойчивого сервиса предусматривали распиливание диапазона выдаваемых адресов в некотором процентном соотношении между двумя серверами (80 на 20, например). Первый сервер раздавал адреса, второй тихо был в резерве. Когда первый становился недоступен, включался в систему второй и «поддерживал штаны», пока первый снова не становился доступным. Безусловно, если «распилить» диапазон 50/50, то теоретически всё хорошо. НО! Во-первых, а что если вами используется больше половины диапазона? Во-вторых, вспомним, что в жизни есть резервации (запомненные пары MAC-IP), которые делаются не просто так, а с какой-то целью (на этот адрес прописываются особые разрешения в firewall и т.д.). Если для компа запомнен адрес из одной половины, то его нет во второй половине, очевидно.
Вторая классическая схема – кластер. Это когда у вас есть несколько железок, а поверх них некоторая программная надстройка, которая обеспечивает единую виртуальную «точку входа» для сервиса. Короче, клиент обращается к DHCP всегда одинаково, а виртуалка с сервисом может практически мгновенно съебаться с одного физического сервака на другой абсолютно незаметно для этого самого клиента. Это нехило страхует от физических проблем, а страховку от логических обеспечивают своевременные бэкапы и предыдущая схема. Но дорого и не избавляет от проблем с резервациями в случае сочетания с предыдущей схемой.
И третий вариант, который предлагает нам виндовый сервер начиная с версии 2012. Два сервера полностью дублируют друг-друга. При этом возможно как распределение нагрузки в определенном процентном соотношении, так и «горячее резервирование», при котором резервный сервер исправно реплицируется с основным, но запросы не обрабатывает до отказа основного. Справедливости ради: linux тоже так умеет. И в той и в другой ОС такая связка может состоять только из двух серверов, однако сервер может участвовать уже в максимум 31 связке. Также при желании можно пошаманить с репликацией файлов dhcp.leases и dhcp.static в linux, но зачем городить колхоз, когда есть готовые решения?
Пара схем. Одна область (scope) может участвовать только в одной связке одновременно.
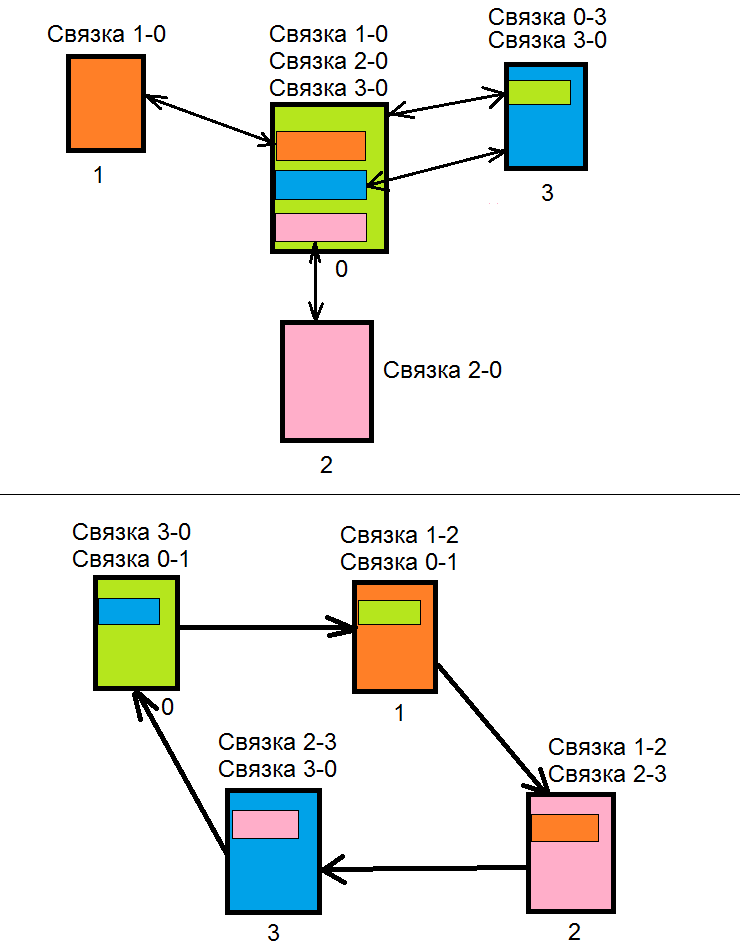
Я буду рассматривать настройку виндового варианта. Просто потому, что использую его. Предполагается, что работающий DHCP у вас уже есть, просто вы дозрели до того, что хотите сделать failover. Сервер1 – на нем работает dhcp сейчас, Сервер2 – пустой.
Из граблей – резервации не реплицируются автоматом, их надо пинать руками (на области, на том сервере, где делали изменения ПКМ и «реплицировать эту область»). Все дополнительные настройки области (добавления новых опций dhcp, например) тоже требуют пинка для репликации. Есть вроде отдельная софтина, которая делает это автоматом, но меня, как практически единоличного админа DHCP, устраивает и этот вариант.
В чем разница «hot standby» и «load balance». Для объяснения нам потребуется знать о параметре maximum client lead time (MCLT). Вы его задаете при настройке failover.
Мой телеграм канал о том, как выглядит работа систменого админитсратора:
https://t.me/sysadmin_how_it_is
А моё впечетление от DHCP Failover тут
В данном посте я буду идти от сильного упрощению к менее сильному упрощению, и в конце приближусь к правде, мне кажется, это логичнее, чем сразу углубляться в протокол.
Для начала, что делает DHCP (Dynamic Host Configuration Protocol – протокол динамической настройки узла). С помощью этой штуки сетевые устройства могут получать IP-адрес и другие сетевые настройки автоматически. Работает этот протокол по клиент-серверной модели. В самом общем случае это выглядит так:
Самое простое, что обычно нужно — посмотреть, пингуется ли адрес, открыт ли порт, трассировочку извне сделать — узнать нет ли траблов у провайдера. Не у всех разрешен vpn домой.
Я пользуюсь termux на телефоне (андроид) или iSH на apple. Даже без рутования почти полноценный линух, сетевые команды есть/ставятся из пакетов. Телнетом на порт можно постучаться. Всегда под рукой, на работе вы или в дороге, что ещё нужно. Недавно вот бота нашла — @LookinGlassBot тоже огонь штука.
Ну и в целом, есть такая штука как Looking Glass — это веб мордочки, поднятые разными владельцами сетей, чтоб можно было глянуть на вашу сеть как бы из их сети, не дозваниваясь до сетевых инженеров. Пинг, трассировка, bgp маршруты — вот это всё. Но тут надо хорошо понимать, чей именно Looking Glass вам нужен и зачем. Если абстрактно «извне» попинговать, то хватит termux в телефоне.
Мой канал в телеграм: https://t.me/sysadmin_how_it_is
Эту статью я сначала опубликовала на пикабу. Там она вылежалась и обросла комментариями. С некоторыми косметическими правками теперь и тут.
Статья ориентирована на уровень студентов и начинающих админов. Я не буду затрагивать вопросы безопасности или конкретной реализации, но постараюсь затронуть те вопросы, которые «проскакивают», либо вовсе игнорируют популярные статьи типа «что такое DNS». Читать далее DNS — это просто
Здесь собраны ссылки за долгое время, потому может попасться старьё. При победе над ленью список обновляется. Читать далее Полезные ссылки
Это история не о победе, а скорее о troubleshooting’е. Читать далее Сервер перестал отвечать на ARP-запросы
Ошибка 720 у меня возникла после установки Eset (точнее после удаления каспера и замены его на eset). Есть два способа лечения: классический и неклассический. Первый мне помог в прошлый раз, когда устанавливался касперский, но в этот раз пришлось искать лучше. На всякий случай: испробовано только на Win8.1 Читать далее Ошибка подключения vpn 720